
A webcam and Kinect is used for the vision system. The combined visual and depth information allows the objects to be identified and the correct grasping points identified.
The objects are identified and the images segmented, after which the object can then be classified using a decision tree structure. Once the object has been identified the correct grasping strategy can be applied and the optimum grasping points identified. A summary of the algorithm developed is given below, specific details of each part are given later in this section:

The below figures shows the segment depth profile, the RGB vision shows the object identified, and bounding box applied and the grasping points determined. Here the banana which is gripped using a grasping mechanism is shown:

A depth and RGB image for the eraser, where suction is used. this shows the object centre has been choose as the suction point.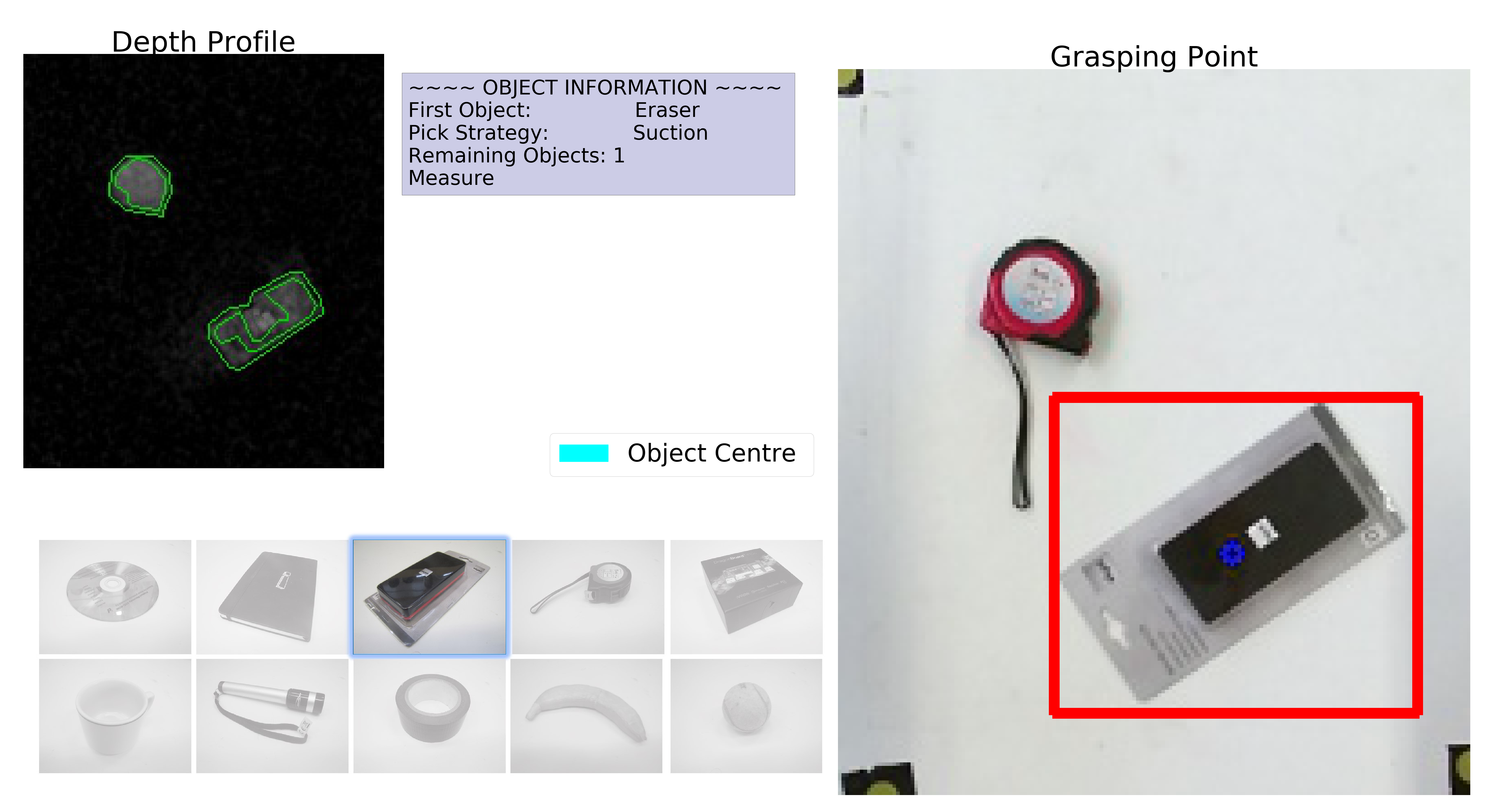
The specific details of the Object identification algorithmn summarised above are now given:
- Take RGB and Depth Images
- Process images
i) Crop and filter images
ii) Zero image with empty calibration images
iii) Extract contours using edged detection
iv) Organise contours with respect to height and geometry
–> Return normalised clean images and contour images - Match RGB data with depth information
create class object which extracts object features if object is detected (RGB, aspect ratio, fill, measure of how circular, etc.) - Object recognition performed based on previously extracted data
Local stored database of mapping of vision parameters to object - Picking strategy determined by object recognised:
- Grasping algorithm
i) First node found by closest depth contour point
ii) Possible 2nd grasping points found by drawing perpendicular line from the 1st node
iii) 2nd grasping point found if grasping points are at the same height and midpoint of the 1st and 2nd grasping point is taller than the grasping point - Picking
Find centre of RGB or depth image of object (the use of which depends on which is most reliable for a given object
- Grasping algorithm
- Convert to real world coordinates
Convert pixels to real world robot world coordinates and send the co-ordinates to the inverse kinematic solver and enable the arm movement.